2023
Paragraphica is a context-to-image camera that uses location data and artificial intelligence to visualize a "photo" of a specific place and moment. The camera exists both as a physical prototype and a virtual camera that you can try.



The viewfinder displays a real-time description of your current location, and by pressing the trigger, the camera will create a scintigraphic representation of the description.
On the camera, there are three physical dials that let you control the data and AI parameters to influence the appearance of the photo, similar to how a traditional camera is operated.






The camera operates by collecting data from its location using open APIs. Utilizing the address, weather, time of day, and nearby places. Comining all these data points Paragraphica composes a paragraph that details a representation of the current place and moment.
Using a text-to-image AI, the camera converts the paragraph into a "photo".
The resulting "photo" is not just a snapshot, but a visual data visualization and reflection of the location you are at, and perhaps how the AI model "sees" that place.
Interestingly the photos do capture some reminiscent moods and emotions from the place but in an uncanny way, as the photos never really look exactly like where I am.

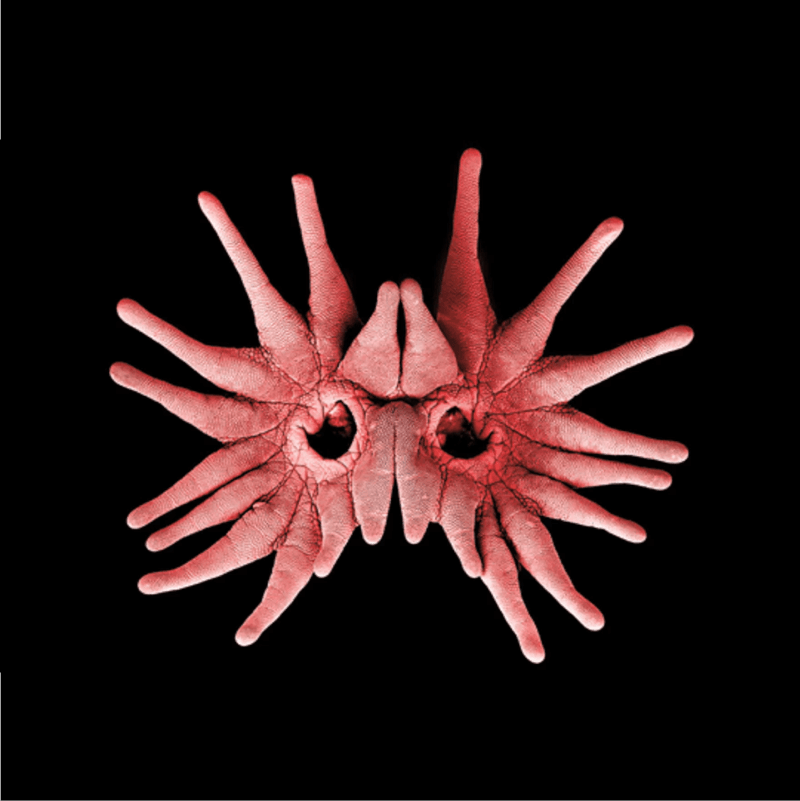
The star-nosed mole, which lives and hunts underground, finds light useless. Consequently, it has evolved to perceive the world through its finger-like antennae, granting it an unusual and intelligent way of "seeing." This amazing animal became the perfect metaphor and inspiration for how empathizing with other intelligences and the way they perceive the world can be nearly impossible to imagine from a human perspective.
As AI language models are increasingly becoming conscious, we too will have limited imagination of how they will see the world.
The camera offers a way of experiencing the world around us, one that is not limited to visual perception alone. Through location data and AI image synthesis, "Paragraphica" provides deeper insight into the essence of a moment through the perspective of other intelligences.

The first dial behaves similarly to the focal length in an optical lens but instead controls the radius (meters) of the area the camera searches for places and data. The second dial is comparable to film grain, as the value between 0.1 and 1 produces a noise seed for the AI image diffusion process.
The third dial controls the guidance scale. Increasing guidance makes the AI follow the paragraph more closely. In the analogy of a traditional camera, the higher the value, the "sharper," and the lower, the "blurrier" the photo, thus representing focus.






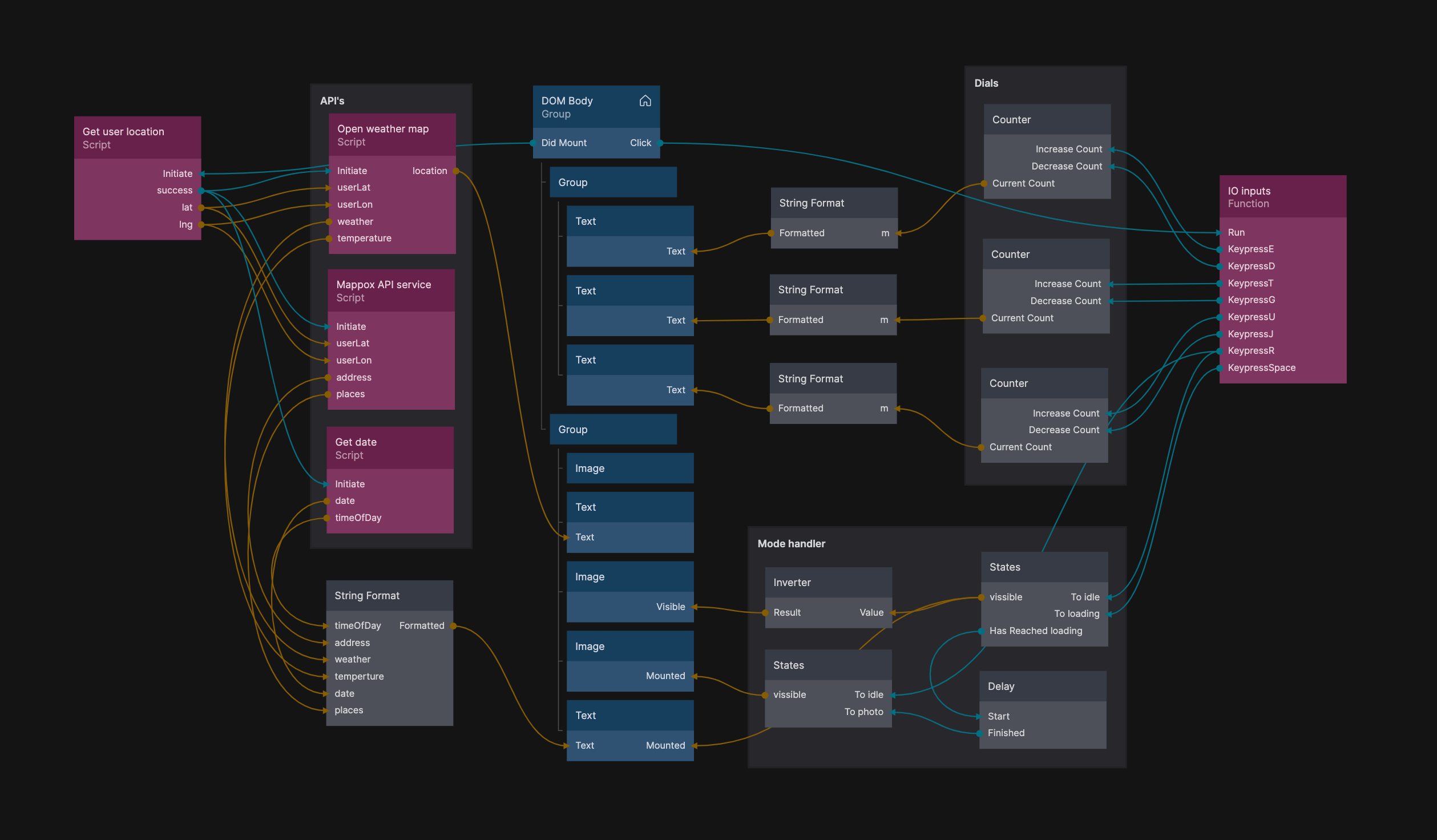
Above is a screenshot from Noodl, that I used to build the web app that communicates between the camera and the multiple APIs to generate the location-based prompt and the image itself.
Hardware:
Raspberry Pi 4, 15-inch touchscreen, 3D printed housing, custom electronics
Software:
Noodl, pyhton code, Stable Diffusion API
Introducing – Paragraphica! 📡📷
— Bjørn Karmann (@BjoernKarmann) May 30, 2023
A camera that takes photos using location data. It describes the place you are at and then converts it into an AI-generated "photo".
See more here: https://t.co/Oh2BZuhRcf
or try to take your own photo here: https://t.co/w9UFjckiF2 pic.twitter.com/23kR2QGzpa
Selected Works

Project AliasProject type

Terraform TableProject type

Occlution GrotesqueProject type

TrajectoriesProject type

PyrographProject type

ParagraphicaProject type

ObjectifierProject type

UAE PavillionProject type

CIID NetworkProject type

News GlobusProject type

Discharge NoiseProject type

AbstractProject type